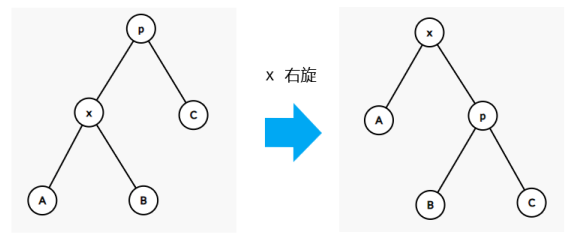
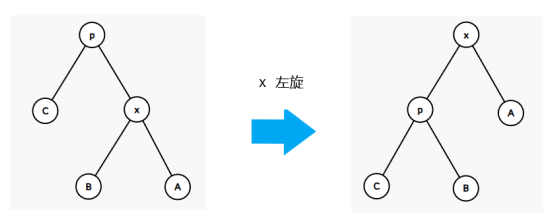
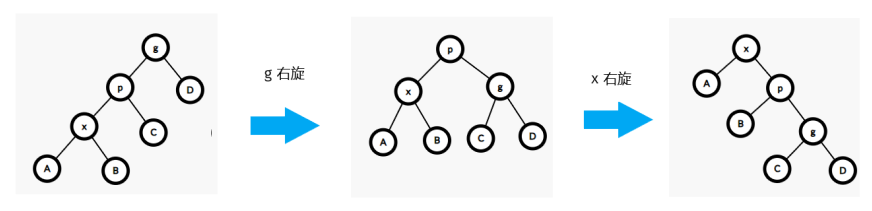
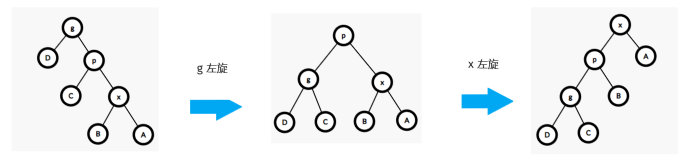
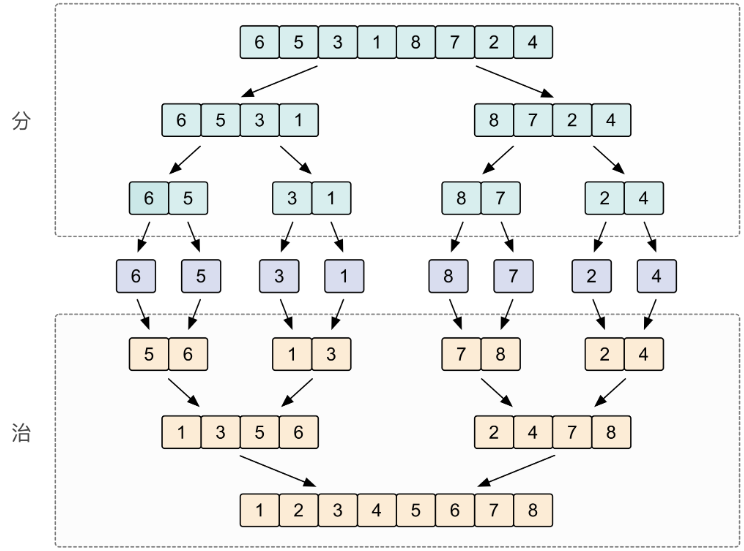
defquicksort(items) : iflen(items) <= 1 : return items # pivot = items[len(items) // 2] pivot = items[random.randint(0, len(items) - 1)] # 更快 smaller = [x for x in items if x < pivot] larger = [x for x in items if x > pivot] same = [x for x in items if x == pivot] return quicksort(smaller) + same + quicksort(larger)
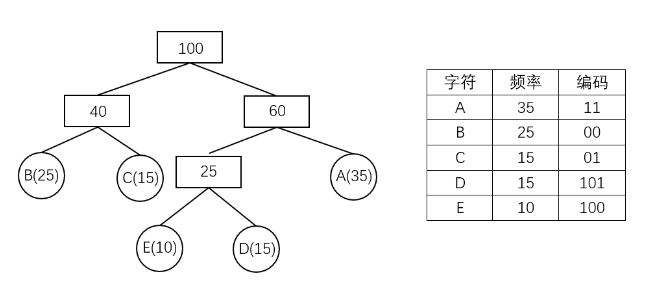
//Huffman Tree's Node structHuffmanTreeNode { char character;// character int frequency;// frequency of char character HuffmanTreeNode* left;//left Node HuffmanTreeNode* right;//right Node HuffmanTreeNode() { character = 0; frequency = 0; left = 0; right = 0; }
HuffmanTreeNode(char _character, int _frequency)//Init Node with character and frequency { character = _character; frequency = _frequency; left = 0; right = 0; }
HuffmanTreeNode(HuffmanTreeNode* _left, HuffmanTreeNode* _right)//Init Node with left and right { character = 0; frequency = _left->frequency + _right->frequency; left = _left; right = _right; }
HuffmanTreeNode(char _character, int _frequency, HuffmanTreeNode* _left, HuffmanTreeNode* _right)//Init Node with character, frequency, left and right { character = _character; frequency = _frequency; left = _left; right = _right; } };
structless//HuffmanTreeNode* compare with frequency less compare { booloperator()(HuffmanTreeNode*& left_node, HuffmanTreeNode*& right_node)const { return left_node->frequency < right_node->frequency; } };
structgreater//HuffmanTreeNode* compare with frequency greater compare { booloperator()(HuffmanTreeNode*& left_node, HuffmanTreeNode*& right_node)const { return left_node->frequency > right_node->frequency; } };
std::string data; std::map<char, int> cnt; while (fin >> data)//read data { for (auto& x : data)//foreach data and calculate the frequency of character { cnt[x] += 1; } }
std::priority_queue<HuffmanTreeNode*, std::vector<HuffmanTreeNode*>, greater> q;//use priority_queue to build tree for (auto& [character, frequency] : cnt) { HuffmanTreeNode* node = newHuffmanTreeNode(character, frequency); q.push(node); }
while (!q.empty())//build HuffmanTree { if (q.size() > 1)//keep building tree { auto left_node = q.top(); q.pop(); auto right_node = q.top(); q.pop(); auto node = newHuffmanTreeNode(left_node, right_node); q.push(node); } else// find root { root = q.top(); q.pop(); } }